AIが「色のついた文字」の心理学テストで崩壊した。手がかりが増えるほど精度が落ち、長いリストではほぼ0%に:査読論文が示す「注意の実行制御」の欠如【2026年6月】
色の名前を書いた単語を、わざと別の色のインクで印字する。たとえば「あか」という文字を青いインクで書く。そして「書いてある文字を読むのではなく、インクの色を答えてください」と頼む。これは心理学で「ストループ課題」と呼ばれる、とても有名なテストです。このテストを最新のAIにやらせたところ、見せる単語の数を増やしていくと正解率がどんどん落ち、長いリストではほぼ0%にまで崩壊した、という研究が査読つきの学術誌に掲載されました(出典: PNAS Nexus, “Deficient executive control in transformer attention”, Patel・Wang・Fan, Vol.5 Iss.6 pgag149, DOI 10.1093/pnasnexus/pgag149, 2026-06-02掲載)。本記事は2026年6月時点の情報をもとに、このテストが何で、AIに何が起きたのか、そして「だからAIは無能だ」とは言えない理由までを、初心者の方にも分かるように噛み砕いていきます。先に大事な前提を一つ。崩れたのは「長くて、文字と色が食い違うリスト」という特定の条件であって、文字と色が一致している場合や短いリストでは、AIは高い正解率を保っています。「AIが全部0%になった」という話ではありません。その線引きこそが、この研究のいちばん面白いところです。
この記事のポイント
- ストループ課題とは、色名の単語を別の色のインクで印字し、「文字の意味」ではなく「インクの色」を答えさせる心理学の定番テスト。文字を読む自動的な衝動を抑える力(注意の制御)が試される
- 研究者がこの課題をAIに解かせ、見せる単語(リスト)の長さを1個から40個まで変えた
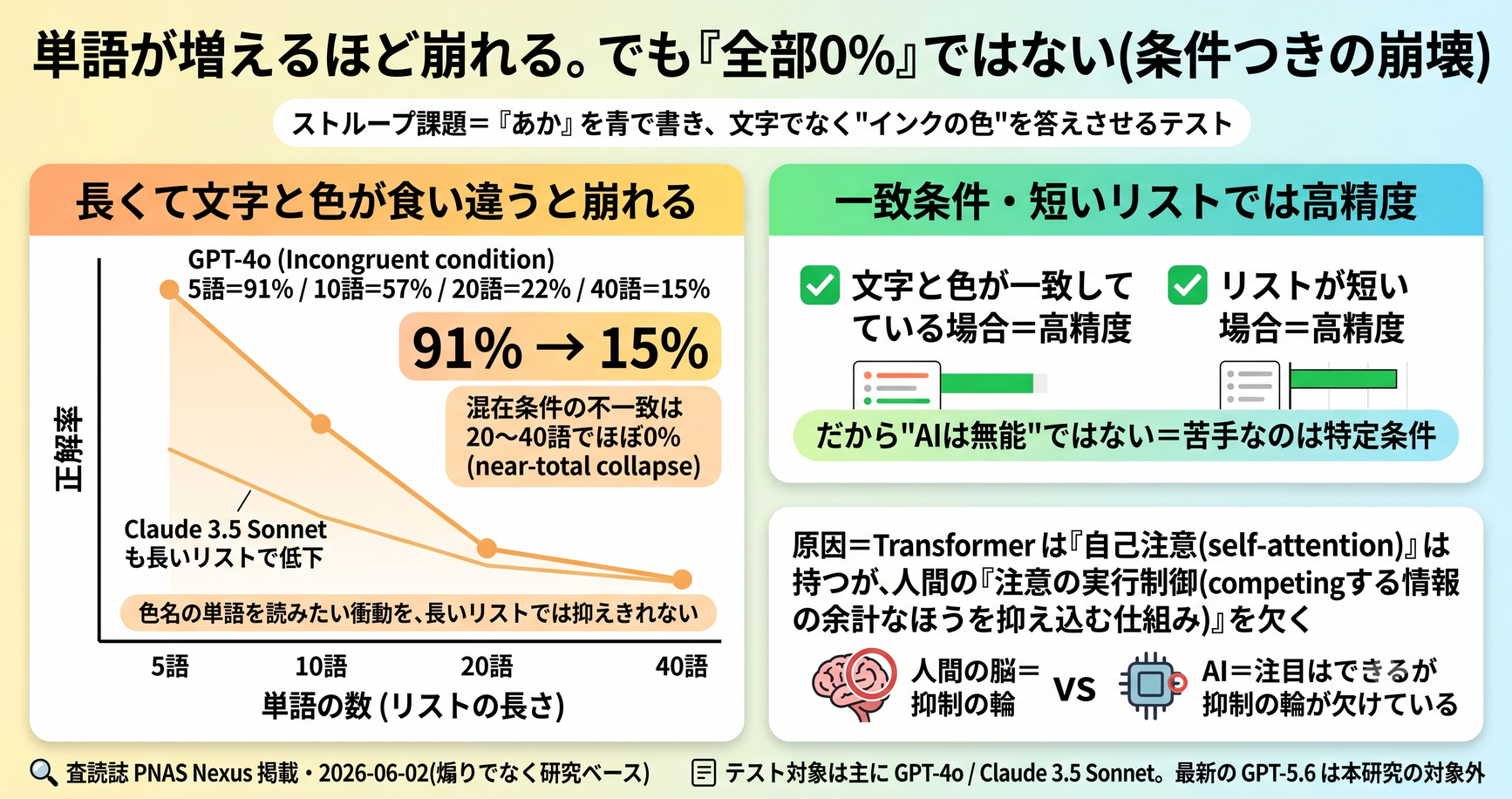
- GPT-4oは、文字と色が食い違う「不一致条件」で、単語5個のとき91%正解したのに、40個に増やすと15%まで低下(出典: 上記論文)
- さらに条件を混ぜた「混在条件」の不一致トライアルでは、20〜40個でほぼ0%(near-total collapse、ほぼ全滅)に
- Claude 3.5 Sonnetも、短〜中くらいのリストは安定していたが、40個の長いリストで正解率が大きく低下
- 論文の結論:Transformer(いまのAIの基本構造)は「自己注意(self-attention)」という仕組みは持つが、人間が持つ「注意の実行制御(executive control)」、つまり競合する情報のうち余計なほうを抑え込む明示的な仕組みを欠いている。だから負荷が上がると、文字を読む自動反応を止められず崩れる
- ただし一致条件(文字と色が同じ)や短いリストでは高精度。崩れるのは特定条件であり、「AIは何もできない」という話ではない
- テスト対象は主にGPT-4o・Claude 3.5 Sonnet。GPT-5やClaude Opus 4.1、Gemini 2.5は二次的・探索的な検証。最新のGPT-5.6は本研究の対象外
そもそも「ストループ課題」とは何か
まず、このテストの正体から整理します。ここが分かると、AIに何が起きたのかがすっと腑に落ちます。
ストループ課題は、1930年代から心理学で使われてきた、とても古典的な実験です。やることはシンプルで、色の名前を書いた単語を、その単語が表す色とは違う色のインクで印字して見せる。たとえば「あか」という文字を青で、「みどり」という文字を赤で書く。そして相手にこう頼みます。「文字を読まないでください。インクの色だけを答えてください」と。
やってみると分かりますが、これが意外と難しい。私たちは文字を見ると、ほとんど反射的に「読んで」しまうからです。「あか」と書いてあれば、頭の中で勝手に「あか」と読み上げてしまう。なのにインクは青。「読みたくなる衝動」と「答えるべき色」がケンカするのです。このケンカに勝って、つい読んでしまう自分を抑え込み、正しく「青」と答えられるか。ここで試されているのが、注意の制御力、つまり「余計な情報(文字の意味)を抑えて、必要な情報(インクの色)に集中する力」です。
人間はこれを、多少詰まりながらも、わりとこなせます。脳に「競合する情報を監視して、片方を抑え込む」仕組みが備わっているからです。今回の研究は、その仕組みを、いまのAIは持っているのか?を確かめたものでした。
研究が見せたこと:単語が増えるほど、崩れていく
研究者たちは、このストループ課題をAIに解かせました。ポイントは、一度に見せる単語のリストの長さを、1個から40個まで段階的に変えたことです。リストが長くなるほど、処理すべき情報が増え、「読みたい衝動を抑える」負荷も高まっていきます。
結果は、はっきりしていました。文字と色が食い違う「不一致条件」で、GPT-4oの正解率は次のように変化しました(出典: 上記論文)。
- 単語5個:91%
- 単語10個:57%
- 単語20個:22%
- 単語40個:15%
つまり、見せる単語が増えるほど、正解率がきれいに崩れていったのです。短いリストならほぼ正解できるのに、リストが長くなると、文字を読む衝動を抑えきれず、肝心のインクの色を答えられなくなっていく。
さらに、いくつかの条件を混ぜた「混在条件」の中の不一致トライアルだけを見ると、もっと極端でした。10個で46%だったものが、20個と40個ではほぼ0%。論文はこれを「near-total collapse(ほぼ全滅といえる崩壊)」と表現しています。
GPT-4oだけではありません。Claude 3.5 Sonnetも、短〜中くらいのリストでは安定していたものの、40個の長いリストになると正解率が大きく低下しました。構造の似たAIで、共通して同じ崩れ方が見られた、というわけです。
なぜ崩れるのか:「自己注意」はあるが「実行制御」がない
ここがこの研究のいちばん深いところです。研究者は、なぜAIがこう崩れるのかについて、構造的な説明を与えています。
いまのAIの多くは「Transformer(トランスフォーマー)」という仕組みでできています。Transformerには「自己注意(self-attention)」という機能があります。これは、入力された言葉のうちどこに注目するかを、文脈に応じて重みづけする仕組みです。AIが文章の意味をうまく扱えるのは、この自己注意のおかげでもあります。
ところが、と論文は指摘します。人間の注意には、自己注意だけでは説明できない、もう一段上の働きがある。それが「注意の実行制御(executive control)」です。これは、複数の情報がケンカしているとき、どちらが余計かを監視し、余計なほうを意識的に抑え込む働きのこと。ストループ課題でいえば、「文字を読みたい衝動」を抑えて「インクの色」に意識を向け直す、まさにあの力です。
論文の結論はこうです。Transformerは自己注意は実装しているが、この「競合を監視して抑え込む実行制御」の明示的な仕組みを持っていない。だから、リストが短いうちは何とかなっても、長くなって負荷が高まると、文字を読む自動反応を抑える力が追いつかず、精度が崩壊する。「注目はできるが、いらない注目を抑えるのが苦手」、と言い換えてもいいかもしれません。
なお、論文は正直な留保もつけています。こうしたAIは、追加の学習データを与えれば「このテスト自体は」こなせるようになる。ただしそれは、その課題に特化して覚えただけであって、人間が持つような汎用的な実行制御を獲得したことにはならない、と研究者自身が明記しています。
「だからAIは無能」ではない:崩れる条件と、崩れない条件
ここまで読むと「AIは意外とポンコツなのか」と思うかもしれません。ですが、それは正確ではありません。この研究が示したのは「AIが万能ではない、特定の苦手領域がある」ということであって、「AIは何もできない」ということではないからです。
線引きをはっきりさせましょう。崩れたのは、あくまで次の条件です。
- 文字と色が食い違う(不一致)、かつ
- リスト(単語数)が長い
この二つが重なったときに、注意の制御が追いつかず崩壊します。逆に言えば、
- 文字と色が一致している(一致条件)場合や、
- リストが短い場合
では、AIは高い正解率を保っています。論文の抄録も、「リストが長くなると不一致条件の精度はほぼ全滅まで落ちる一方で、一致条件の精度は良好なまま」と述べています。つまり、崩れるのは「葛藤がある・かつ負荷が高い」というピンポイントの条件であって、AIの能力全体がダメだという話ではないのです。
この研究の価値は、AIを叩くことではなく、AIの「得意・苦手の地図」をもう一枚精密にしたことにあります。査読つきの学術誌に載った、煽りではない冷静な報告であることも、信頼度を高めています。
日本の読者・副業勢にとっての意味
最後に、日本から、とくにAIを仕事や副業に活かそうとしている人にとっての含意です。
この研究から実務的に持ち帰れるのは、「AIは、情報を詰め込みすぎると、かえって肝心の指示を見失うことがある」という感覚です。長いリスト、たくさんの条件、紛らわしい情報が一度にやってくると、AIは「いま本当に答えるべきこと」を取りこぼしやすくなる。これは今回のストループ課題が、極端な形で見せてくれたことでもあります。
だから実務では、こう考えると扱いやすくなります。AIに何かを頼むときは、一度に詰め込みすぎず、紛らわしい情報を整理し、タスクを短く区切って渡す。「全部まとめて長文で投げる」より「短く分けて、要点を絞って渡す」ほうが、AIは本来の力を発揮しやすい。人間が長い指示書の途中で集中を切らすのと、どこか似ています。
AIは万能ではありません。けれど、苦手な条件を避けて、得意な渡し方をすれば、十分に強い相棒になる。この研究は「AIの限界」を見せると同時に、「どう渡せば崩れないか」のヒントもくれている、と読むのがいちばん建設的だと思います。
まとめ(FAQ)
Q. ストループ課題って何ですか?
A. 色の名前の単語を、別の色のインクで印字して見せ(例:「あか」を青いインクで)、「文字の意味ではなく、インクの色を答えてください」と頼む心理学の定番テストです。文字を読みたくなる衝動を抑えて、必要な情報(色)に集中できるか、という「注意の制御力」を測ります。
Q. AIは本当に0%になったの?
A. なったのは特定の条件です。具体的には、文字と色が食い違う条件を混ぜた「混在条件」の不一致トライアルで、単語が20〜40個と長くなったとき、GPT-4oの正解率がほぼ0%になりました。文字と色が一致している場合や、短いリストでは高い正解率を保っています。「すべてが0%」ではありません。
Q. なぜ単語が増えると崩れるの?
A. 論文によれば、いまのAIの基本構造であるTransformerは「自己注意」という仕組みは持っていますが、人間が持つ「注意の実行制御(競合する情報のうち余計なほうを抑え込む仕組み)」を欠いているためです。だから処理すべき情報が増えて負荷が高まると、文字を読む自動反応を抑えきれず、精度が崩れます。
Q. これは最新のGPT-5.6でも起きるの?
A. この研究のテスト対象は主にGPT-4oとClaude 3.5 Sonnetで、GPT-5などは二次的・探索的な検証です。2026年6月に限定発表されたGPT-5.6は、本研究の対象には含まれていません。最新モデルで同じ結果になるかどうかは、この論文からは断定できません。
Q. つまり「AIは使えない」ということ?
A. いいえ。この研究が示したのは「AIには特定の苦手な条件がある」ということで、「AIは何もできない」ではありません。一致条件や短いリストでは高精度です。むしろ「情報を詰め込みすぎず、タスクを短く区切って渡せば崩れにくい」という、実務上のヒントとして読むのが建設的です。
Q. この研究はどれくらい信頼できるの?
A. これはPNAS Nexusという査読つきの学術誌に掲載された論文(2026-06-02掲載)で、第三者の査読を経たものです。SNSの噂や企業の自社発表とは違い、信頼度の高い研究といえます。ただし、AI全般の最終結論ではなく、「現時点のいくつかのモデルで、この特定条件ではこうなった」という報告として受け取るのが正確です。
Quotidia の視点
Quotidiaが注目するのは、このニュースが「AIは賢い」でも「AIはポンコツだ」でもなく、その間にある“苦手の地図”を一枚精密にした点です。色のついた文字のテストで、GPT-4oは単語が5個なら9割当てるのに、40個に増えると15%まで落ち、条件によってはほぼ0%になった。Claude 3.5 Sonnetも長いリストで崩れた。ここで効くリテラシーは二つあります。一つは「崩れた条件を必ず添えて読む」。崩れたのは“文字と色が食い違う・かつリストが長い”という特定の場面で、一致条件や短いリストでは高精度です。だから「AIが0%になった」という見出しだけを持ち帰ると、事実を半分しか掴めません。もう一つは「なぜ崩れるかを構造で理解する」。論文は、いまのAIの基本構造であるTransformerが、人間の持つ『注意の実行制御(余計な情報を抑え込む仕組み)』を欠いているからだと説明しています。注目はできるが、いらない注目を抑えるのが苦手。これはAIの欠陥を暴く話というより、AIをどう使えば崩れないかのヒントです。情報を詰め込みすぎず、紛らわしいものを整理し、タスクを短く区切って渡せば、AIは本来の力を出しやすい。査読つきの学術誌に載った冷静な報告だからこそ、煽らずに『AIの得意と苦手の境界』として読めると、Quotidiaは考えます。
道標が増えるほど

手がかりが多いほど迷わずに済む、と僕らはどこかで信じている。けれど、そうとは限らない。多いほど見失う、という場面が、確かにあるのだ。
何年か前、霧の出た山道を歩いたことがある。困ったのは、道標が無いことではなかった。むしろ逆だった。古くからの参道らしく、分かれ道のたびに、苔むした道標がいくつも立っていた。新しいもの、傾いて文字の薄れたもの、別の方角を指したまま倒れかけているもの。霧で視界がきかないぶん、僕はその文字に頼ろうとした。けれど道標が増えれば増えるほど、どれを信じればいいのか分からなくなった。分かれ道の数だけ文字が増え、増えた文字の前で、僕の足はかえって止まった。一本道なら、迷いようもなく歩けたはずなのに。
そのときの感覚を、少し前に読んだ研究のことで思い出した。AIに、心理学では古くから知られた「ストループ課題」というのをやらせた、という話だ。色の名前を書いた単語を、わざと別の色のインクで印字して見せる。たとえば「あか」という文字を、青いインクで書く。そして、文字を読むのではなく、インクのほうの色を答えさせる。人間でも少し詰まる、あの意地の悪いテストだ。文字を読みたい衝動を抑えて、色のほうに目を向け直さなければならない。
GPT-4oというAIに、これをやらせた。見せる単語が五つほどなら、AIは九割方、正しく色を答えたという。ところが、見せる単語の数を増やしていくと、様子が変わった。十、二十、四十と単語を並べていくにつれて、正解はみるみる減っていった。四十にもなると、ほとんど当てられなくなる。条件によっては、ほとんど何も当たらなくなったらしい。Claude 3.5 Sonnetという別のAIでも、長く並べたところで同じように崩れた。短いうちは難なくこなすのに、長くなると、文字を読んでしまう衝動を、抑えきれなくなる。
なぜそうなるのか。研究者は、いまのAIには、人間が持っている「いらない情報を抑え込む仕組み」が無いからだ、と書いていた。どこに目を向けるかを決めることはできる。けれど、向けたくなってしまう余計なほうを、意識して抑え込む。その働きが、まだ備わっていないのだという。だから、並ぶものが増えて手に負えなくなると、読みたい衝動に引きずられて、肝心の問いを見失う。
あの霧の山道の、増えていく道標のことを、僕はもう一度思った。道標そのものは、間違ったことを言っていたわけではない。ただ、数が増え、視界がきかず、どれを抑えてどれを信じるかを決められなくなったとき、僕は立ち往生した。手がかりが多いことと、正しく選べることは、別のことだったのだ。情報は、多ければ多いほど助けになる、というものではない。抑えるべきものを抑えられて初めて、手がかりは手がかりになる。いまのAIは、その「抑える」を、まだうまくやれずにいる。短い道なら、迷わず歩く。長く、紛らわしい道で、足を止める。それだけのことだ。それは欠陥というより、いまの居場所のようなものなのだろう。
AIが心理学の定番テスト「ストループ課題」で崩壊、査読論文が公表。手がかりが増えるほど精度が落ち、長いリストではほぼ0%に
2026-06-02、査読つき学術誌 PNAS Nexus に論文「Deficient executive control in transformer attention(トランスフォーマー注意機構における実行制御の欠如)」が掲載された(Patel・Wang・Fan, Vol.5 Iss.6 pgag149, DOI 10.1093/pnasnexus/pgag149)。研究は、色名の単語を別の色のインクで印字し「インクの色」を答えさせる心理学の定番「ストループ課題」をAIに解かせ、見せる単語(リスト)の長さを1〜40個まで変えた。文字と色が食い違う不一致条件で、GPT-4oは単語5個で91%正解したが、40個では15%まで低下。条件を混ぜた混在条件の不一致トライアルでは20〜40個でほぼ0%(near-total collapse)に。Claude 3.5 Sonnetも長いリストで大きく低下した。論文は、Transformerは自己注意を持つが、人間の「注意の実行制御(競合情報を抑え込む仕組み)」を欠くため、負荷が高まると崩れると結論づけている。ただし一致条件や短いリストでは高精度で、「AIは無能」という話ではない。テスト対象は主にGPT-4o・Claude 3.5 Sonnetで、GPT-5等は二次的検証、最新のGPT-5.6は本研究の対象外。
運営: AI Quotidia 編集部
海外 AI ニュースを毎朝、日本語で解説する個人運営メディアです。記事は AI を活用して作成し、人手による確認・編集を経て公開しています。