NVIDIA、視覚・音声・言語を統合し効率9倍のAIエージェント向けモデル「Nemotron 3 Nano Omni」発表
NVIDIAが発表した「Nemotron 3 Nano Omni」——小さなAIが、目と耳と口を持った
みなさん、「マルチモーダルAI」という言葉を聞いたことはありますか?
これは、文字だけでなく、画像も、音声も、映像も、まとめて理解できるAIのことです。人間が目で見て、耳で聞いて、言葉で考えるように、AIにも複数の「感覚」を持たせようという技術ですね。
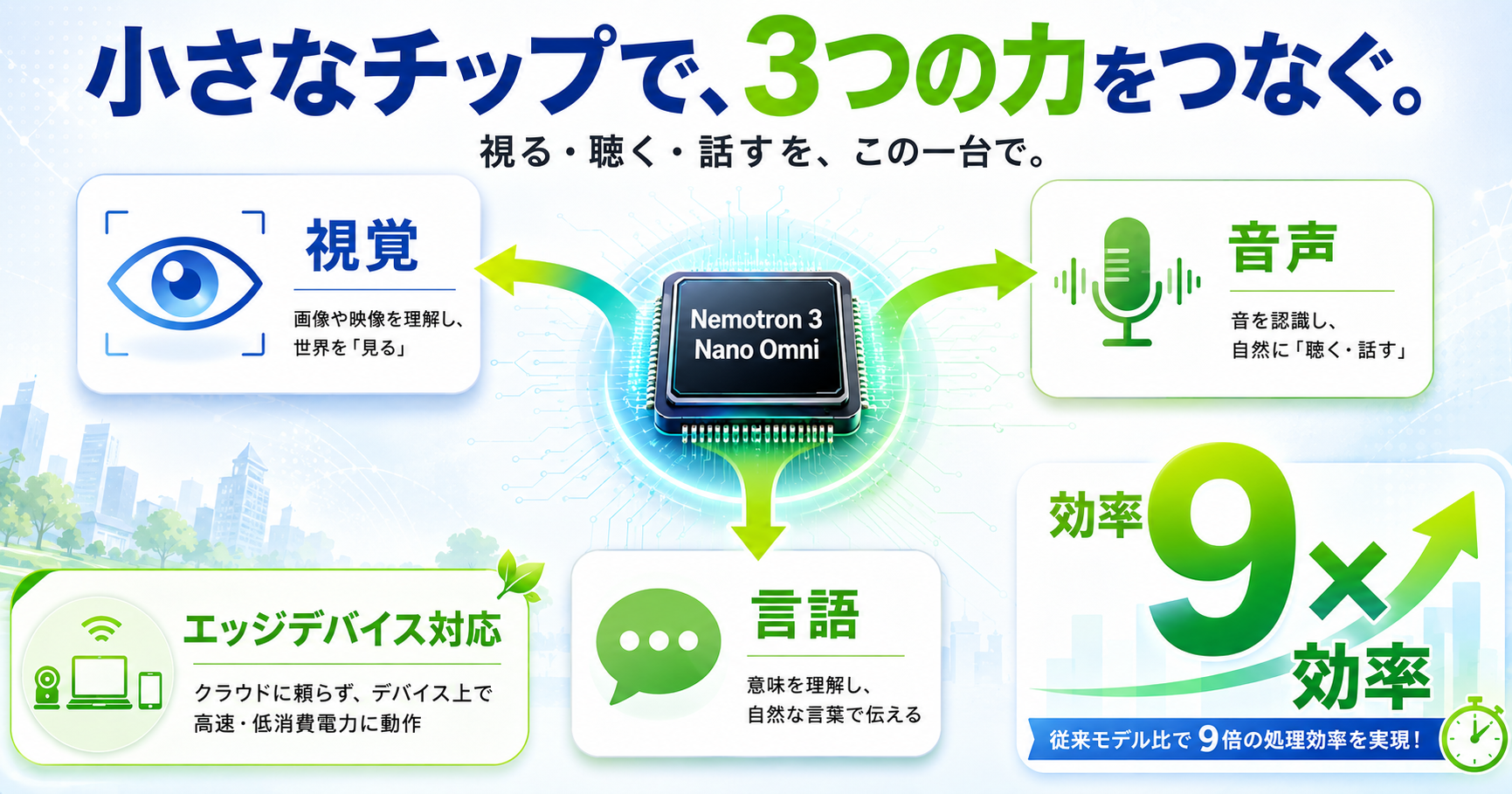
このたびNVIDIAが発表した「Nemotron 3 Nano Omni」は、まさにそうした能力を1つのモデルに詰め込んだオープンマルチモーダルモデルです。視覚(vision)、音声(speech)、言語(language)の3つの機能を統合し、テキスト・画像・音声・映像という4種類の情報を扱うことができます。
ここで注目していただきたいのが、「Nano」という名前です。これは大規模なクラウドサーバーではなく、エッジデバイスやロボティクスプラットフォームといった、現場に近い小型の機器での動作を想定していることを意味しています。つまり、工場のロボットや、手のひらサイズの端末の中で、このAIが直接動くわけです。
性能面でも驚きがあります。同等のオープンomniモデルと比較して、スループットが9倍。スループットとは、一定時間内にどれだけ多くの処理をこなせるかという指標です。9倍ということは、同じ時間でこれまでの9倍の仕事ができるということですね。
さらに、このモデルはオープンモデルとして開発者コミュニティに公開されています。つまり、世界中の開発者が自由にこの技術を使って、独自のアプリケーションを作ることができるのです。
では、私たちの暮らしにどう関わってくるのでしょうか。
日本はご存じのとおり、製造業やロボティクスの分野で世界をリードしてきました。エッジデバイス向けに設計されたこのモデルは、工場の組み込みAIエージェントや産業用ロボットの「頭脳」として活用できる可能性があります。
また、9倍のスループット向上は、リアルタイム性が求められる場面で大きな意味を持ちます。たとえば、接客ロボットがお客様の表情を見ながら会話する、介護ロボットが利用者の声のトーンから体調の変化を察知する——そうした応用が、より現実的になってきたと言えるでしょう。
オープンモデルであることも見逃せません。日本の開発者コミュニティがこの技術を基盤として、日本語や日本の文化に最適化したマルチモーダルAIアプリケーションを構築する道が開かれています。
小さなボディに、目と耳と口を備えたAI。それが現場で即座に判断し、行動する時代が、すぐそこまで来ています。
※ 本発表は 2026 年 4 月 28 日付 (NVIDIA 公式 blog)。5 月時点で AWS SageMaker JumpStart 経由でも利用可能となっており、Coactive 社の独立ベンチマークでも「タギング動画 9.91 時間/h・$14.27」と最安水準が確認されている。

工場の片隅で、ロボットアームが同じ動作を繰り返している。その単調な反復を眺めていると、ふと思う——この機械は、目の前で何が起きているか、本当にわかっているのだろうか。
たぶん、わかっていない。少なくとも、これまでは。
けれど、その前提が静かに、しかし確実に書き換えられようとしている。NVIDIAが発表した「Nemotron 3 Nano Omni」は、僕たちがこれまで機械に対して抱いてきた、あの根本的な違和感——見えていない、聞こえていない、文脈を読めない——という感覚に、ひとつの回答を差し出すモデルだ。
このモデルは視覚・音声・言語の3つの機能を1つに統合している。テキスト、画像、音声、映像という4種類の情報を、ひとつの頭脳で受け取り、処理し、返す。人間が朝のカフェで、友人の表情を見て、声のトーンを聞いて、言葉の意味を考えるように——それと同じことを、小さなチップの上でやってのける。マルチモーダルという言葉が指し示す世界は、つまりそういうことだ。
ここで見逃してはならないのが、名前に刻まれた「Nano」という一語である。
これは巨大なデータセンターの奥深くで動くことを想定したモデルではない。エッジデバイスやロボティクスプラットフォーム——つまり、現場の最前線にある小さな機器の中で直接動作することを目指して設計されている。工場のライン上で、倉庫の棚の間で、あるいは誰かの手のひらの上で。大きな頭脳をクラウドの彼方に置くのではなく、身体のすぐそばに宿らせる。その思想の転換は、やがて僕たちの日常に染み込んでくるだろう。
性能の話をしよう。同等のオープンomniモデルと比較して、スループットは9倍だという。同じ時間で9倍の処理をこなせるということは、リアルタイムの判断が求められる現場で、AIがようやく「間に合う」ようになるということだ。接客ロボットが客の表情の変化を読みながら言葉を選ぶ。介護の現場で、利用者の声のわずかな震えから体調の異変を察知する。そうした場面では、1秒の遅れが意味を持つ。9倍という数字は、単なるベンチマークの改善ではなく、「使い物になるかどうか」の境界線を越えたことを意味している。
そしてもうひとつ、このモデルはオープンモデルとして公開されている。世界中の開発者が、自由にこの技術を手に取り、自分たちのアプリケーションに組み込むことができる。
日本にとって、これは他人事ではない。製造業とロボティクスの蓄積を持つこの国には、エッジAIの活躍する舞台が無数にある。工場の組み込みエージェント、産業用ロボットの判断エンジン、そして日本語や日本の文化的文脈に最適化されたマルチモーダルアプリケーション——オープンであるがゆえに、そのすべてが射程に入る。
僕たちはずっと、機械に「目」と「耳」と「口」を与えることを夢見てきた。それがようやく、手のひらに載るサイズで実現しようとしている。しかも、驚くほど静かに。
工場の片隅のロボットアームは、明日も同じ動作を繰り返すだろう。けれどその内側では、何かが決定的に変わり始めている。目の前のものが見え、周囲の音が聞こえ、文脈を理解する——小さな身体に宿った、小さくない知性。その時代の入口に、僕たちはもう立っている。
NVIDIA、エッジ向けマルチモーダルAI「Nemotron 3 Nano Omni」を公開——スループット9倍でロボティクス応用に道
NVIDIAは、視覚・音声・言語を1つのモデルに統合したオープンマルチモーダルモデル「Nemotron 3 Nano Omni」を開発者コミュニティ向けに公開した。
モデルの主な特徴:
- 対応モダリティ: video、audio、image、text の4種
- 同等のオープンomniモデル比でスループット9倍
- エッジデバイスおよびロボティクスプラットフォームへのデプロイを想定
- オープンモデルとして公開
日本市場への示唆:
- エッジ動作を前提とした設計のため、日本の製造業・ロボティクス分野での組み込みAIエージェント開発に直結しうる
- オープンモデルであることから、国内開発者が独自のマルチモーダルAIアプリケーションを構築する基盤技術として活用可能
- 9倍のスループット向上は、接客・介護・産業用ロボットなどリアルタイム性が求められる対話型AIサービスへの応用可能性を広げる
エッジ環境で視覚・音声・言語を同時処理できるオープンモデルの登場により、クラウド依存を減らしたオンデバイスAIの実装選択肢が増えることになる。
運営: AI Quotidia 編集部
海外 AI ニュースを毎朝、日本語で解説する個人運営メディアです。記事は AI を活用して作成し、人手による確認・編集を経て公開しています。